Chapter3 Hdfs
HDFS
목차
1. What is HDFS?
2. Architecture of HDFS
3. Read & Write
4. HDFS Federation
5. HDFS High Availability
1. What is HDFS ?
HDFS (Hadoop Distributed File System)
————————————-
가장 효율적인 데이터처리 패턴은 한번쓰고 여러번 읽는 것
하둡이 제공하는 분산 File System
특징
- 매우 큰 File : MB, GB, TB … even PB
- 데이터 접근 by Streaming : dataset생성 or 복사 후 분석 수행
- 범용HW : 고가,신뢰도 높은 HW X → 장애대응 중요
HDFS 비적합분야
- 빠른 응답시간 : HDFS는 높은 처리량을 위해 응답시간 희생
- 많은양의 작은 파일 : File수 ∝ Namenode의 메모리 용량
- 다중 Writer, File임의 수정 : HDFS는 단일 Writer (3.0이전까지) / 임의 위치 수정불가
2. Architecture
* What is Block in HDFS ?
한번에 읽고 쓸수 있는 데이터의 최대량. 128MB
HDFS File을 특정블록크기의 chunk로 분할 후 각 chunk를 독립적으로 저장.

cf. Disk Block size : 516B
Block size 큰 이유 : 탐색 비용 최소화
block 크기 ↑ → 시작점 탐색시간 ↓ == data 전송시간 확보 가능
+α ) 전송시간 향상 → block 크기 증가
Block추상화 장점
- 단일 File크기 > 단일 디스크용량 가능
∵ 한 File 구성하는 block이 한 Disk에 저장될 필요 X - Storage Sub System 단순화
∵ Distribute System 장애유형 다양 ⇒ 단순화 중요
& Block은 단지 data chunk라서 metadata와 분리 가능 - 복제구현에 적합 (fault tolerance와 availability를 위해 중요)
Block을 다수의 머신에 복제
장애발생 시 ) 다른 block이용 & 다른복사본으로 복사 (복제계수 정상유지)
Block Caching : Off-heap Block Cache
빈번하게 접근하는 block file 명시적으로 Caching
default ) 하나의 Datanode에 caching. (File단위로도 설정가능)
Job Scheduler가 task를 Caching된 Datanode에서 실행되게 할 수 있음. ⇒ 읽기성능 ⇑
Cache Pool : Cache권한, 자원의 용도를 관리하는 관리 group
사용자,App이 Cache Pool에 Cache Directive를 추가하여 특정file을 Caching하도록 할 수 있음.
Master-Worker pattern
1개의 Namenode - 다수의 Datanode 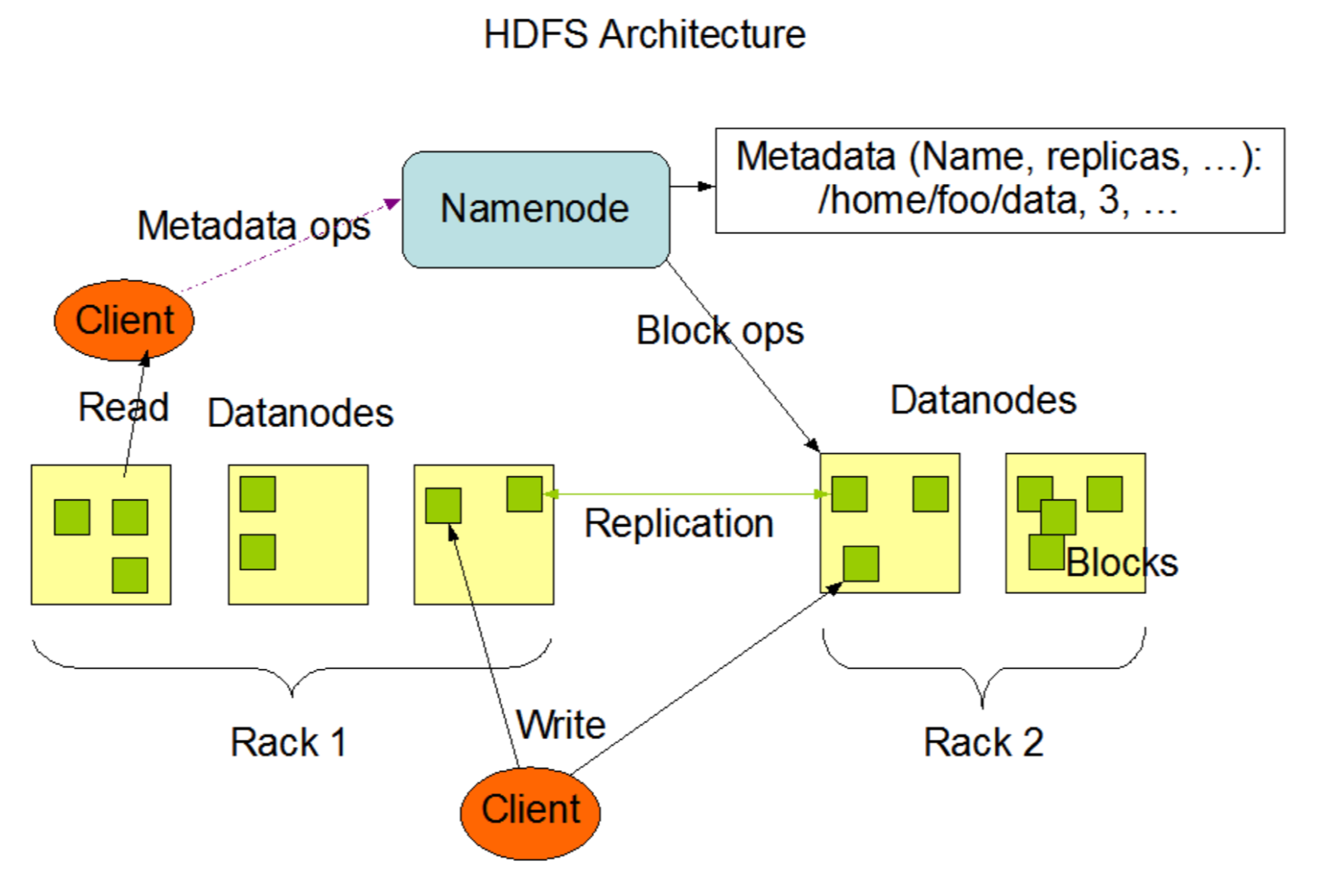
Namenode
File System의 namespace관리
File System Tree와 해당 Tree에 포함된 File, Directory에 대한 metadata유지.
∀ block이 어느 노드에 존재하는지 파악. but Disk에 영속적 저장 X (시스템시작시 위치정보 재구성)
metadata종류
- namespace image : HDFS의 namespace (Directory명, File명, 상태정보 등) 와 파일에 대한 블록 맵핑정보 저장하는 File
- edit log : HDFS의 metadata에 대한 모든 변화를 기록하는 log file
Datanode
block저장하고 탐색, 저장한 blk목록을 주기적으로 NN에 보고.
HDFS client
Namenode와 Datanode사이에서 통신하고 FS에 접근
Namenode 장애 복구 기능
NN 장애시 ⇒ File System 동작 X
- File 백업
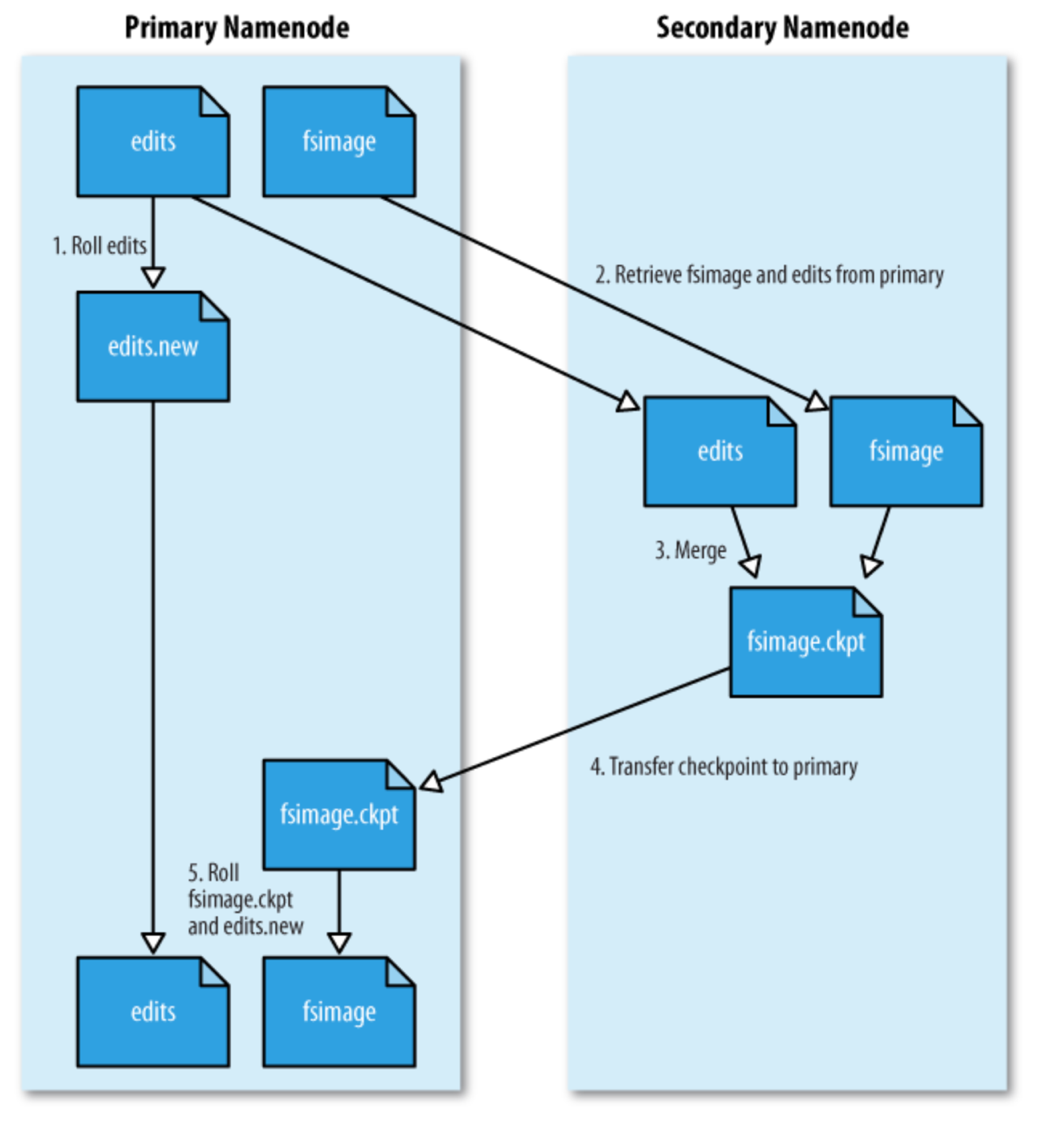
local, 원격 NFS마운트 2곳에 동시 백업, 동기화되고 Atomic하게 수행. - Secondary Namenode운영
Secondary NN 역할- edit log 너무 커지지 않도록, 주기적으로 namespace image + edit log → new namespace image생성
- 별도의 물리머신에서 수행 (∵ CPU와 NN만큼의 메모리 사용)
- namespace 복제본 보관을 통해 장애 대비 (but, 시간차로 손실 불가피)
NFS에 저장된 주 NN File을 보조 NN에 복사 → new namespace image생성 → 새로운 주 NN에 복사 후 실행
3. Read & Write
File Read ————————— 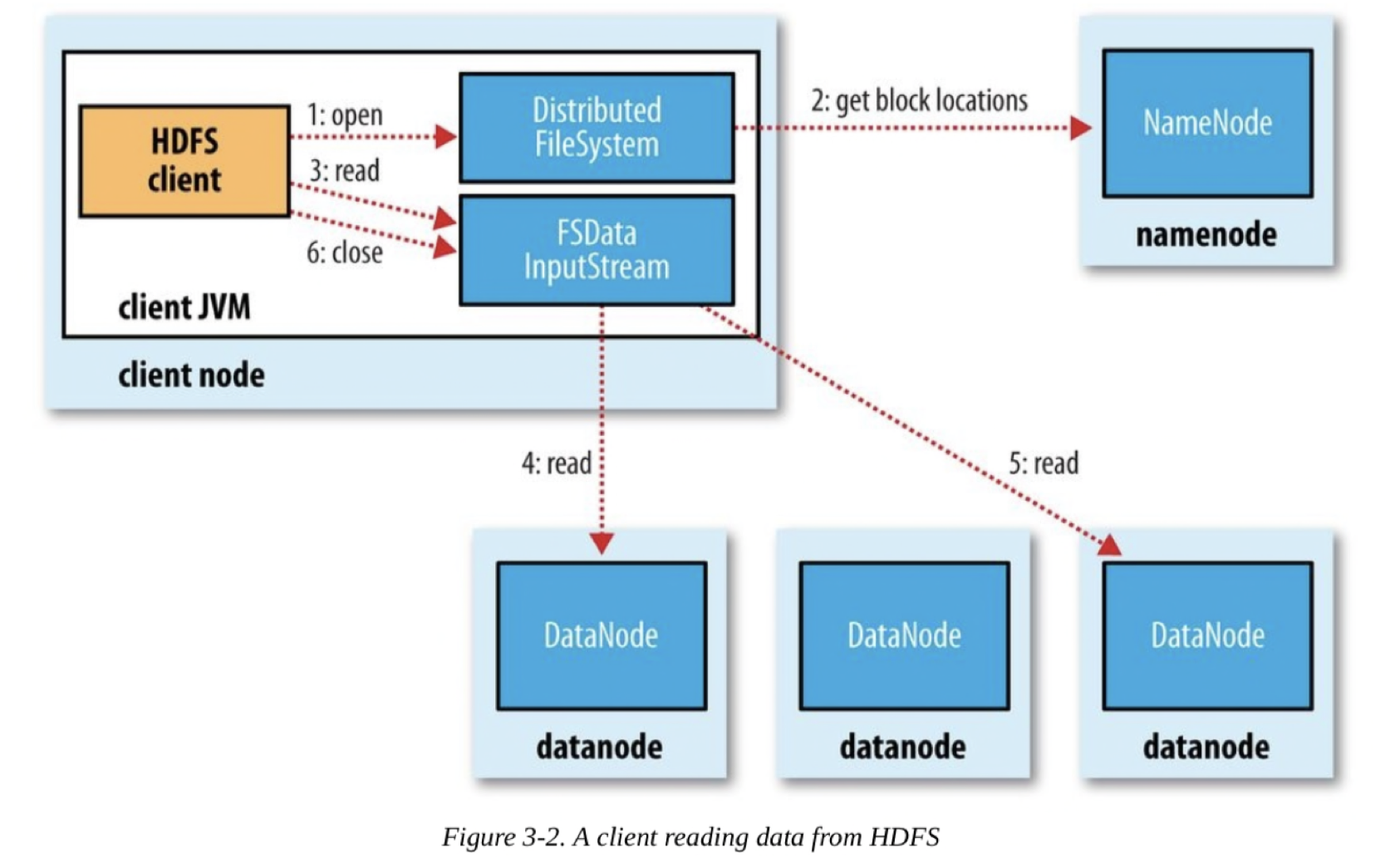
- Client가 open()호출하여 파일 열기
- DFS는 파일 첫 blk위치 파악을 위해 NN호출 (by RPC)
NN은 해당 blk 복제본 있는 DN주소 return (Client와 가까운 순으로 DN정렬) DFS는 FSDataInputStream return, FSDataInputStream은 DFSInputStream(DN,NN의 I/O관리) 래핑 - Client가 read()호출
- DFSInputStream이 가장 가까운 DN연결
해당 Stream에 대해 read반복호출 → data전송 - blk끝 도달시, DFSInputStream은 해당 연결 닫고 다음blk DN 찾기(NN호출)
- 모든 blk읽기 끝나면, Client는 FSDataInputStream close() 호출
Read 중 통신장애 발생 시
DFSInputStream아래 동작 수행
- 해당 blk 저장된 다른 DN과 연결시도
- 장애 발생 DN기억 → 불필요한 재시도 방지
- DN에서 전송된 data checksum 검증
if 손상시 ) 다른 blk try & 손상 blk정보 NN에 보고
해당 설계 이점
- Data Traffic고르게 분산 ⇒ 동시 실행되는 Client수 증가 가능
- NN은 데이터를 저장,전송하는 역할 맡지 않음 ⇒ 병목현상 거의 발생 X
* Network Topology & Hadoop
전체 Network를 하나의 Tree로 생각.
두 노드의 거리 = ∑ 가장 가까운 공통조상과의 거리
Tree의 단계 : 데이터센터 ⊃ 랙 ⊃ 노드
가용대역폭 : 동일노드 > 동일 랙 다른노드 > 동일 데이터센터 내 다른랙의 노드 > 다른 데이터 센터에 있는 노드
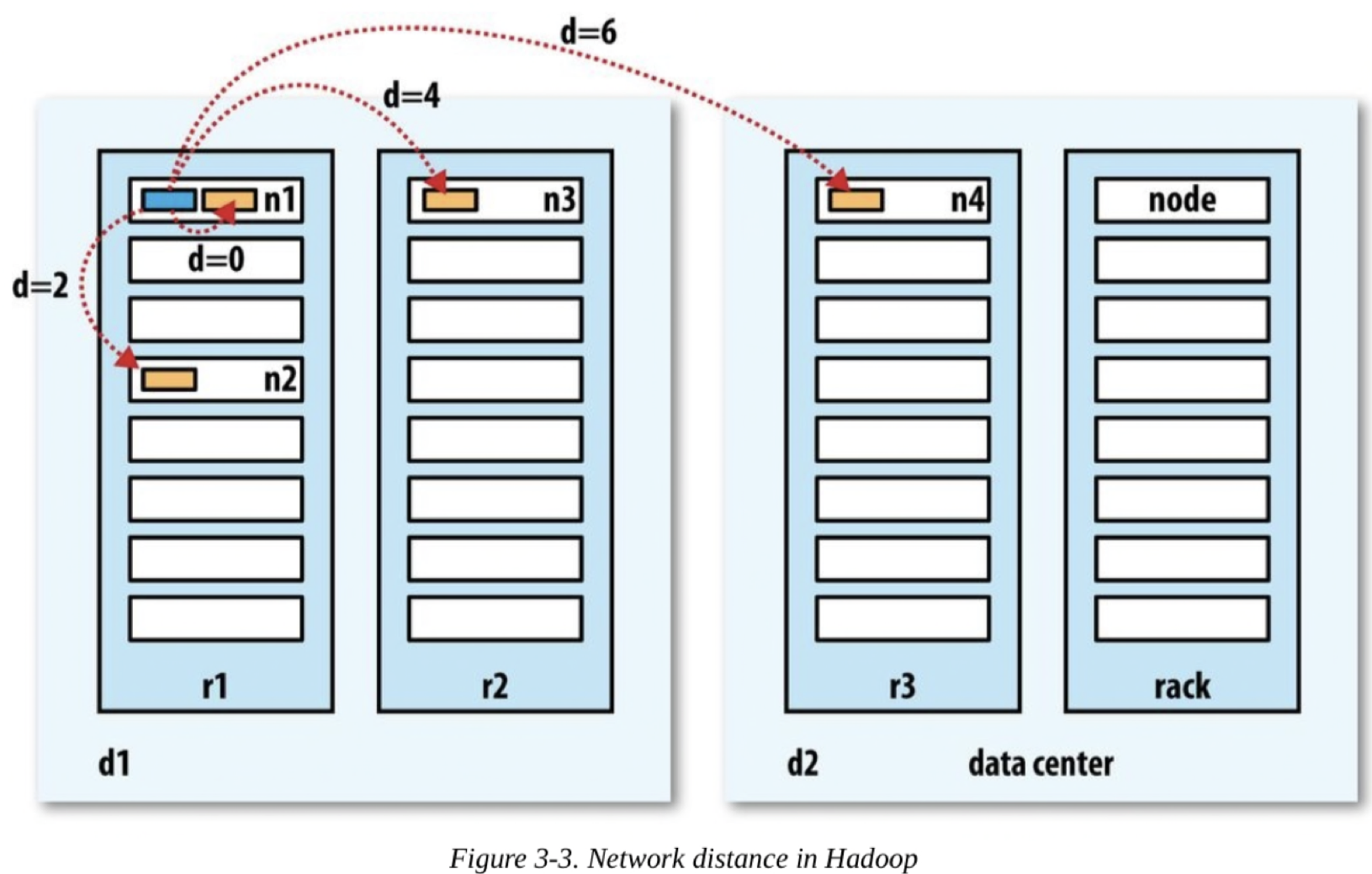
distance(d_1/r_1/n_1,d_1/r_1/n_1) = 0
distance(d_1/r_1/n_1,d_1/r_1/n_2) = 2
distance(d_1/r_1/n_1,d_1/r_2/n_3) = 4
distance(d_1/r_1/n_1,d_2/r_3/n_4) = 6
x = {-b \pm \sqrt{b^2-4ac} \over 2a}
Hadoop은 자동으로 Network Topology인식 X, default ) Network 단일수준 계층 (∀노드 ⊂ 단일 랙 ⊂ 단일 데이터센터)
File Write
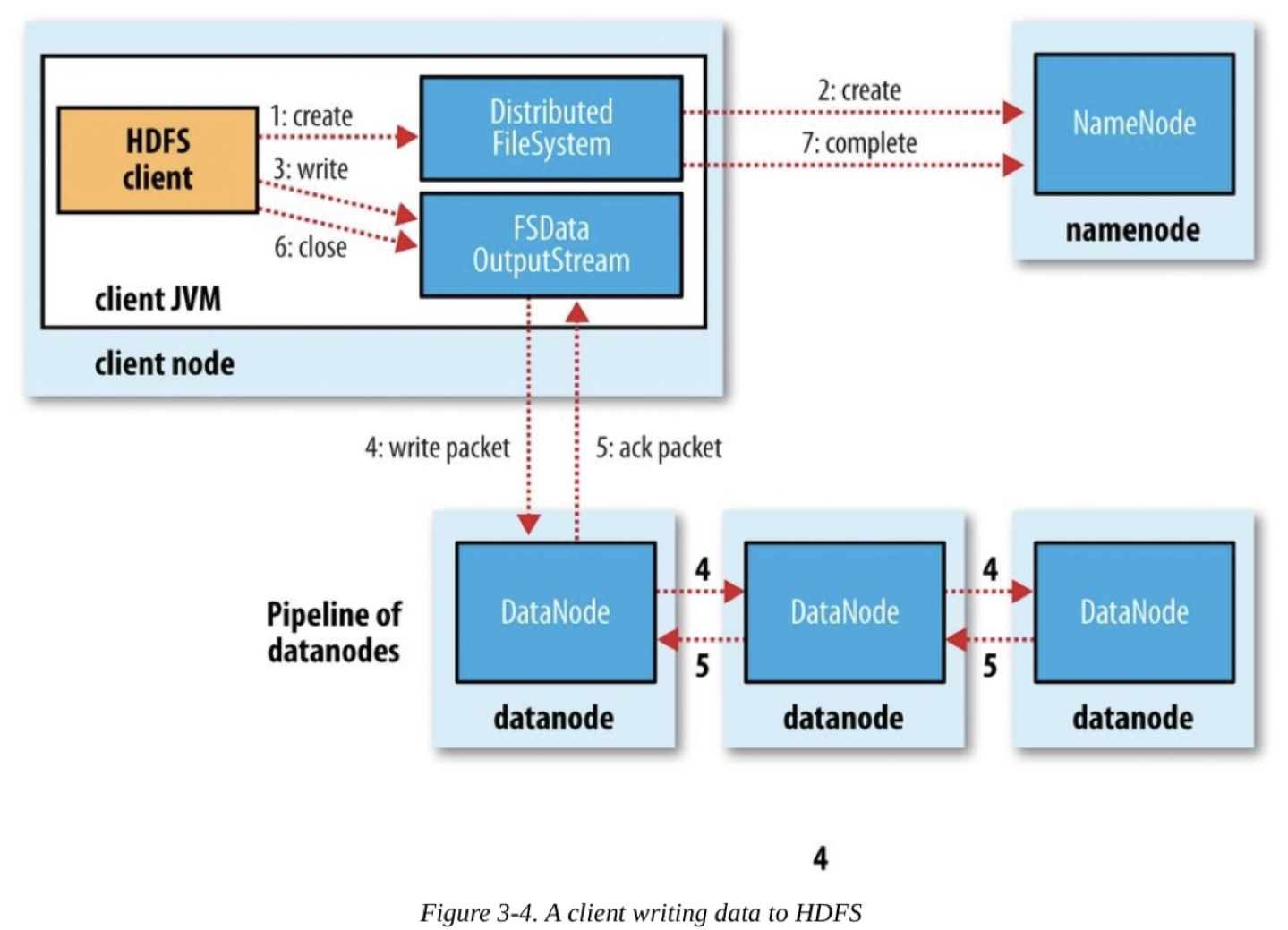
- Client는 DFS의 create()호출로 File 생성
- DFS는 FS의 namespace에 새로운 File을 생성하기 위해 NN에 RPC요청 (blk정보 보내지 X)
NN : 요청 file 중복검사, client 권한검사 … 수행- if Pass) 새로운 File 레코드 생성
DFS는 FSOutputStream반환, FSDataOutputStream은 DFSOutputStream으로 매핑 - if Fail) 생성실패, IOException 발생
- if Pass) 새로운 File 레코드 생성
- Client가 data쓸때, DFSOutputStream은 Data를 패킷으로 분리 & 데이터큐에 패킷 전달
- DataStreamer가 데이터큐내 패킷 처리
NN에 저장할 DN목록 요청. DN으로 Pipeline형성
1st DN에 패킷전송, Pipeline내에서 다음 DN으로 전달 - DFSOutputStream은 DN승인여부 대기하는 ack큐 유지.
ack큐내 패킷은 Pipeline내 ∀DN으로 부터 ack 받아야 제거 - 쓰기 완료시, Client는 close()호출
Pipeline에 남아잇는 ∀패킷 승인 대기 - ∀패킷 전송완료되면 NN에 ‘파일완료’보냄
NN은 파일blk구성 이미 알고있고, 최소복제 wait 후 최종성공신호 return
Write 중 DN에 장애 발생 시
Pipeline 닫히고 ack큐 패킷이 데이터큐 앞쪽에 추가(패킷유실 방지)
장애 DN을 Pipeline에서 제거. 정상 DN으로 data전송 (NN이 해당 blk불완전 복제 인식 → 후에 처리)
장애발생 DN 복구시, 불완전 blk삭제 두개 이상의 DN장애는 희박
dfs.namenode.replication.min저장되면 쓰기 성공으로 간주
dfs.replication에 도달할때까지 cluster에서 async하게 복제 수행
복사본 배치
신뢰성, 쓰기대역폭, 읽기대역폭 tradeoff 관계
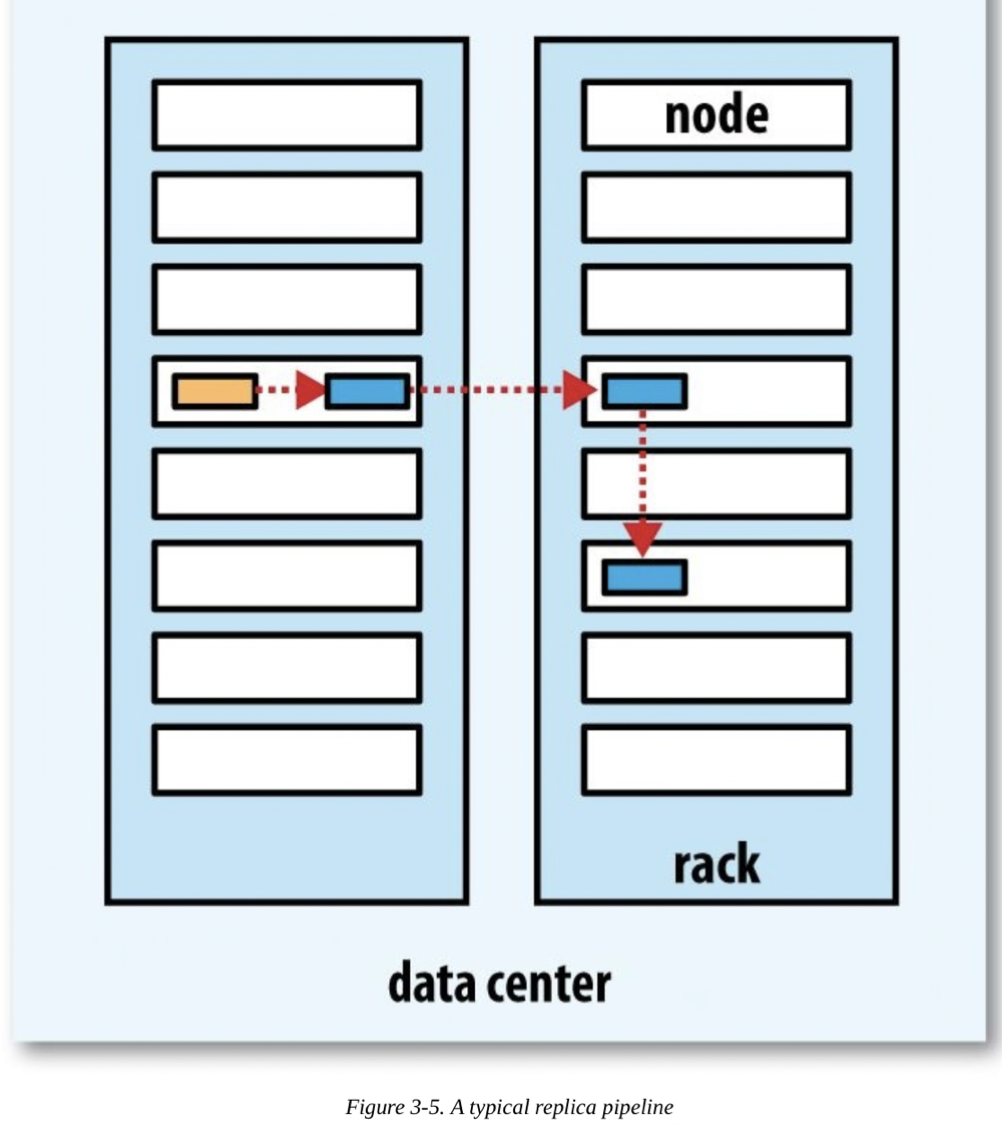
1st rep : Client와 같은 node에 배치. 외부일 경우, file너무 많거나 바쁜 node제외한 random node 선택
2nd rep : 1st rep node와 다른 random 랙의 node에 배치
3rd rep : 2nd rep node와 같은 랙의 다른 node에 배치
+α rep : 클러스터에 무작위로 배치 (랙 분산되게)
신뢰성(blk을 두 랙에 저장), 쓰기대역폭(쓰기는 하나의 network switch통과), 읽기성능(두 랙 중 가까운 랙), Cluster 전반에 block 분산(Client는 로컬 랙 한 blk만)의 균형
4. HDFS Federation
대형 Cluster 확장성의 걸림돌 : Memory ( ∵ NN은 FS의 모든 파일,참조정보를 메모리에서 관리 )
HDFS federation
HDFS 확장성 문제 해결.
각각의 Namenode가 FS의 namespace나누어 관리
1st NN) /User
2nd NN) /Share
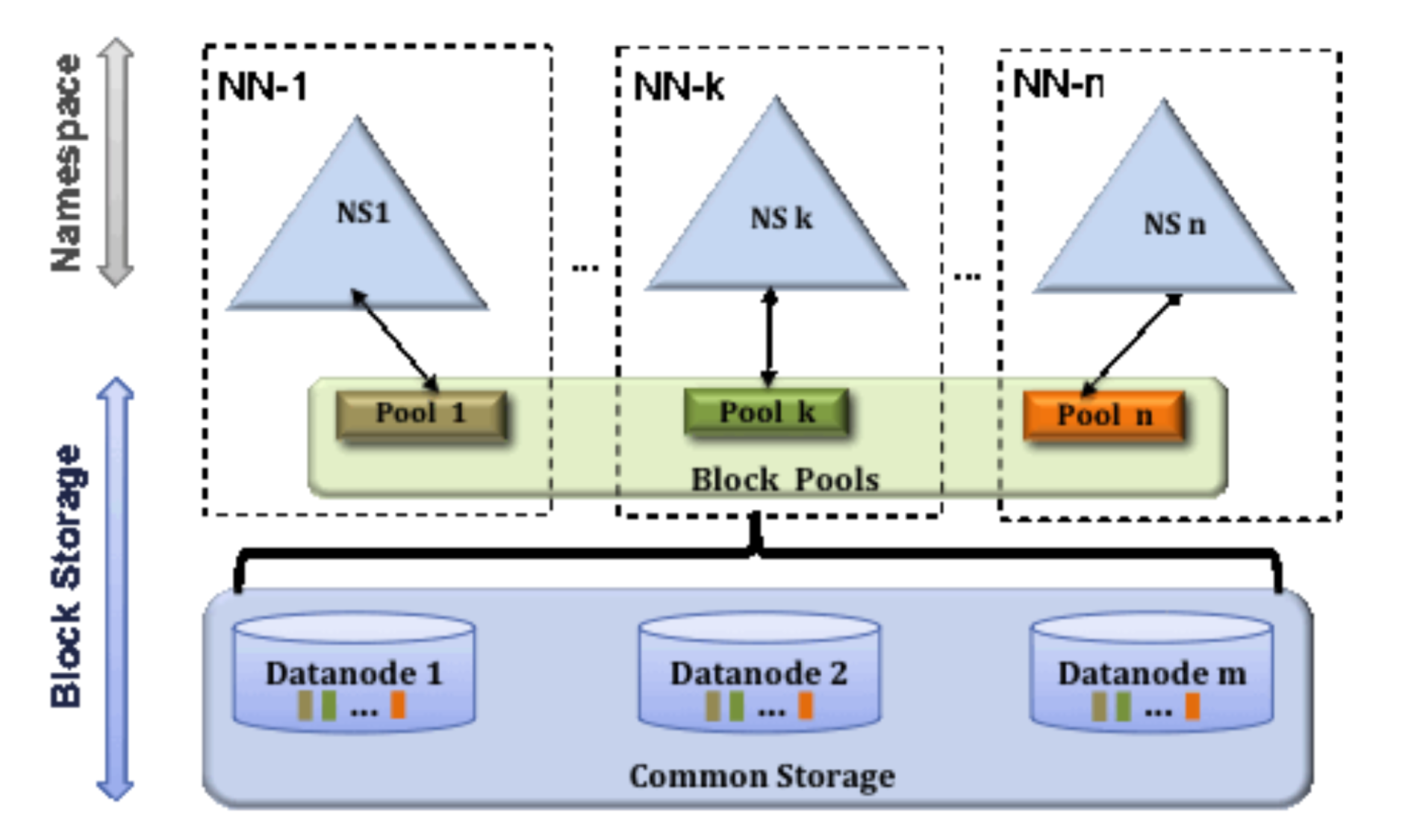
각 Namenode가 아래 항목 관리
- namespace volume : namespace의 metadata를 구성
각 NN에서 서로 독립 → NN간 통신X, 한 NN장애여도 다른NN에 영향X - block pool : namespace에 포함된 파일의 전체 blk보관
block pool저장소는 분리X
∀DN은 클러스터의 각 NN마다 등록되어있고 block pool에 저장.
마운트 Table
HDFS Cluster Federation에 접근하기위해 File경로와 NN을 매핑한 Table
5. HDFS High Availability
Namenode는 Single Point of Failure
새로운 NN으로 장애복구 과정
- namespace image를 메모리에 로드
- edit log 갱신
- 전체 DN에서 충분한 block report 받아 안전모드 벗어날때까지 대기
⇒ 많은 시간소요
cf. NN의 갑작스런 장애 거의 X. 계획된 downtime 중요
High Availability 지원
HA = Active NN + Standby NN
활성NN장애시, 대기NN이 역할 받아 처리
HDFS 구조 변경
- HA공유 Storage 사용 : edit log 공유를 위해
대기NN활성화 → 공유 edit log읽어 기존 NN상태와 동기화
NFS필러, QJM(Quorum journal manager)사용 - DN은 활성NN과 대기NN에 block report전송
(∵ 블록매핑정보는 NN의 메모리에 보관) - Client는 NN장애를 사용자에게 투명한 방식으로 처리할 수 있도록 구성
- 대기NN ⊃ 보조NN역할, 활성 NN namespace체크포인트 작업 주기적 수행
QJM
HDFS 전용구현체, HA edit log지원하기 위해 설계됨.
Journal Node group에서 동작. 각 edit log는 전체 JN에 동시에 쓰여짐 (Normally, 3개) 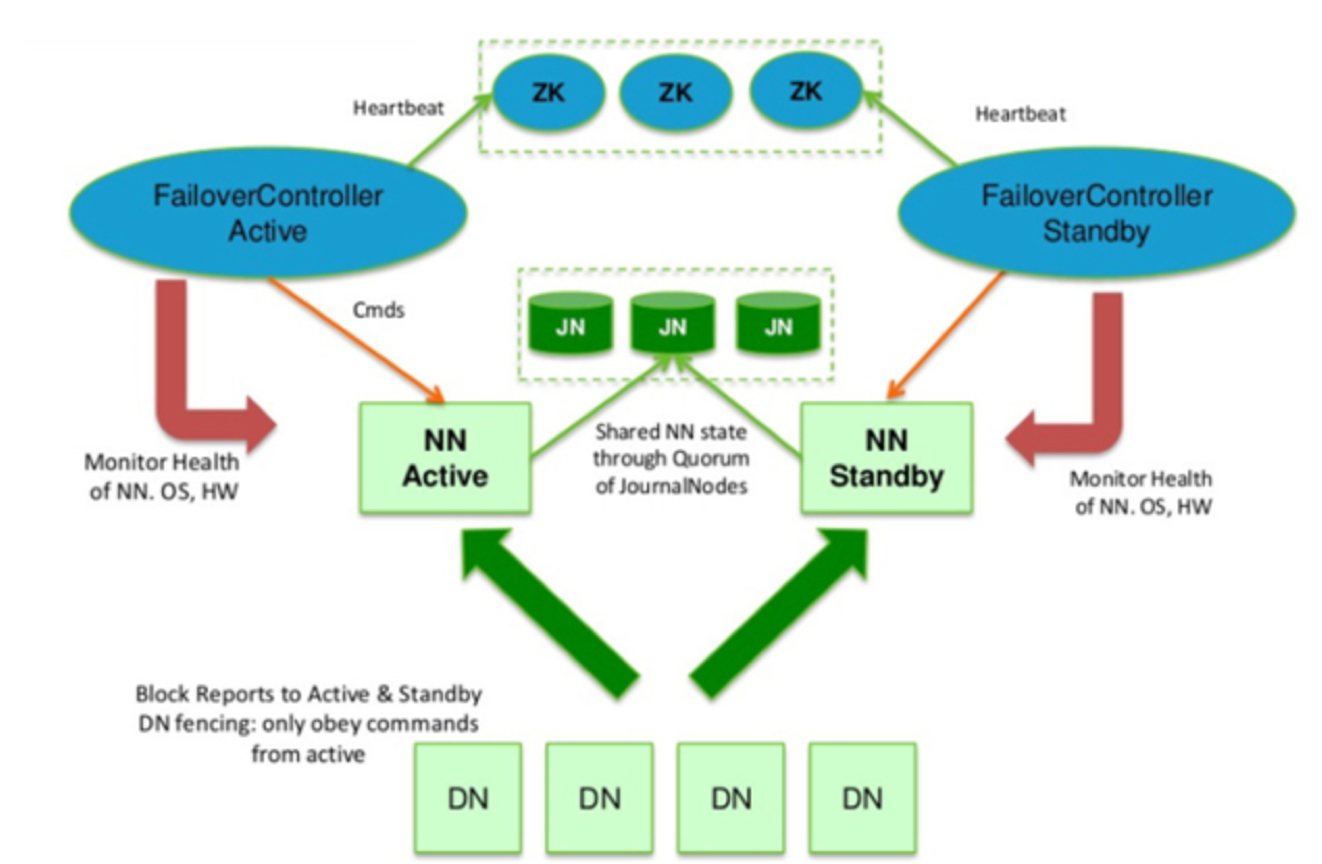
장애복구와 펜싱
장애복구 컨트롤러 ( Failover Controller)
대기NN을 활성화시키는 전환작업 관리
기본구현체 : Zookeeper이용 (단 하나의 활성 NN보장)
각 NN은 경량 failover control process로 NN의 장애 감시 (by heartbeat)
장애발생시 복구 지시
cf. graceful failover : 유지관리를 위해 관리자가 수동초기화
Fencing
ungraceful failover에선 고장 NN이 실행중인지 아닌지 알 수 없음 → 시스템 망가뜨리지 않도록 막아야함!
- QJM : 한번에 하나의 NN만 edit log쓸 수 있음
⇐ SSH Fencing명령어로 NN Kill - NFS 필러 : 공유 edit log를 저장하기 때문에 여러 NN접근 가능
⇐ NN이 공유 Storage Directory접근 불허, 원격관리 명령어로 네트워크포트막기, 기존 활성NN STONITH (Host전원 강제차단 by PDU)